





In questo articolo troverete un sunto dei principi base utilizzati all’interno delle CTU relative a quesiti volti ad individuare i casi di contraffazione del software. Il primo problema che chiunque si troverebbe di fronte è l’analisi di migliaia di righe di codice scritte in un linguaggio che non è detto si conosca alla perfezione.
Oltretutto la legge sul diritto d’autore lascia al CTU ampi spazi pr individuare la compiutezza espressiva del software che, volenti o nolenti, è cosa diversa da un libro o da un film. Quanto troverete scritto in questo articolo non ha nulla a che vedere con la disciplina brevettuale che non si applica ai programmi software.
Il metodo di solito utilizzato all’interno di una CTU prevede una serie di passi condizionati all’esito di alcune verifiche. A monte di tutte le attività ci deve essere la verifica che il software originario che si suppone sia stato copiato sia esso stesso dotato di originalità mentre l’attività finale di valutazione avrà luogo solo se lo step “astrazione/filtraggio/comparazione” avrà fornito risultati positivi ovvero di codice sorgente copiato.
Nel caso in cui le due suddette verifiche diano esito positivo gli step complessivi sono i seguenti:
- Verifica Originalità e presenza di segreti industriali
- Astrazione e definizione perimetro
- Filtraggio
- Comparazione
- Valorizzazione e Valutazioni
Di seguito un semplice diagramma di flusso che esemplifica il percorso logico che di solito viene seguito durante le operazioni peritali.
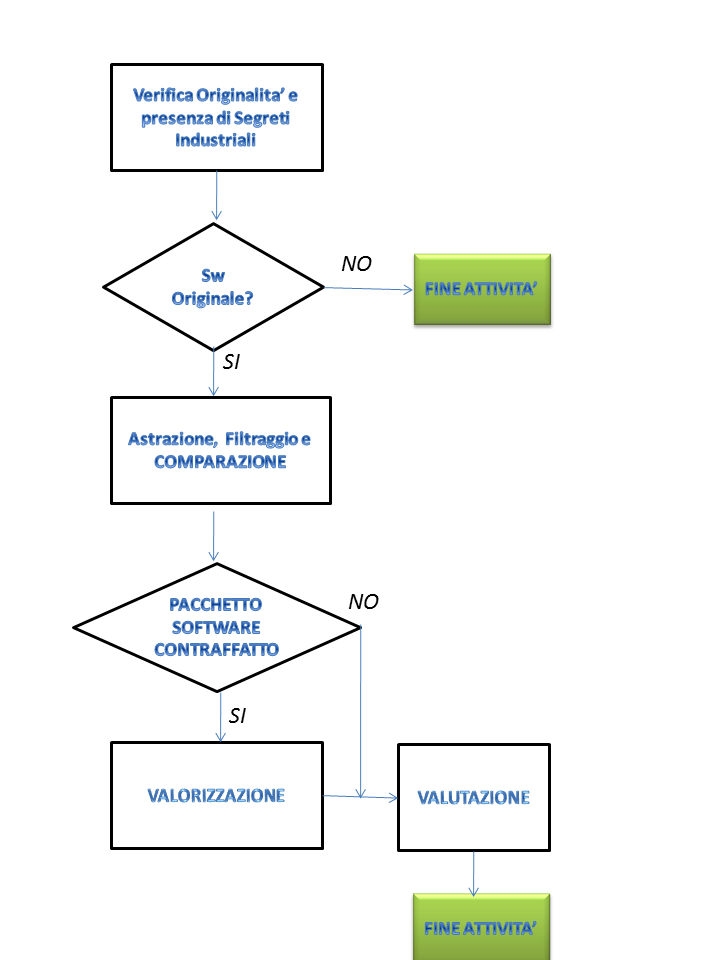
Tale metodologia è nota in letteratura come metodo AFC (Abstraction-Filtration-Comparison) del quale le CTU di solito ereditano le linee generali per poi contestualizzarle nel caso particolare con l’utilizzo di strumenti adeguati al linguaggio di programmazione utilizzato.
Un prodotto che consente l’implementazione del suddetto metodo è Codematch ® della suite Codesuite ® distribuito e venduto dalla SAFE Software Analysis and Forensic Engineering (http://www.safe-corp.biz/).
CodeMatch ® consente di eseguire il confronto tra migliaia di righe di codice sorgente in più directory e sottodirectory e di determinare quali file siano più correlati.
Codematch ® fornisce un report di sintesi che accellera il lavoro in modo significativo evitando l’analisi di migliaia di combinazioni di codice sorgente.
La correlazione dei codici sorgenti è un’attività di tipo deterministico e ripetibile che misura il grado di similitudine dei codici sorgenti. La correlazione globale si ottiene analizzando la correlazione dei suoi elementi tutti importanti. Gli elementi da analizzare sono:
- Statements: Sono le linee di codice che costituiscono la base funzionale del programma. Rappresentano i singoli passi da eseguire per portare a compimento il programma
- Comments: Sono le linee di codice che non forniscono apporto di tipo funzionale ma solo descrittivo.
- Identificativi: Sono i nomi degli oggetti all’interno del codice come le strutture dati e le routine.
- Sequenze di istruzioni: Le istruzioni sono le operazioni di base che si chiede al computer di eseguire mentre la sequenza di istruzioni è la lista degli step del programma nell’ordine in cui devono essere eseguiti.
Il plagio o contraffazione del software nasce, eventualmente, dopo la correlazione di tipo deterministico a valle dell’analisi effettuata da personale esperto.
Sull’originalità di un codice sorgente:
In base all’art 2 comma 8 della legge sul diritto d’autore sono protetti: “programmi per elaboratore, in qualsiasi forma espressi purché originali quale risultato di creazione intellettuale dell’autore. Restano esclusi dalla tutela accordata dalla presente legge le idee e i principi che stanno alla base di qualsiasi elemento di un programma, compresi quelli alla base delle sue interfacce. Il termine programma comprende anche il materiale preparatorio per la progettazione del programma stesso”.
In altri termini non rientrano nella previsione normativa i principi che stanno alla base delle interfacce uomo-macchina del software. A tal proposito il contenzioso tra Apple e Microsoft riguardante l’interfaccia a icone dei propri sistemi operativi è forse l’esempio più significativo.
Il quel caso (United States Court of Appeals for the Ninth Circuit 1994) la corte sentenziò che “Apple non poteva pretendere alcuna protezione sul software legato all’idea di un’interfaccia grafica ad icone che emulasse l’idea di una scrivania (desktop)”.
Ciò posto la scelta tra le possibili forme espressive della soluzione tecnica è concepita come il momento della creazione e si tratta di un linguaggio che non è rivolto alle persone, ma alla macchina. Tale linguaggio può consentire al programmatore un certo numero di gradi di libertà che può essere molto alto per alcuni complessi videogiochi (che a volte sono anche caratterizzati da una trama) mentre piuttosto limitato per software gestionali basati su linguaggi di quarta generazione che utilizzano middleware di tipo grafico.
E’ importante precisare che la registrazione del software nel registro pubblico per i programmi per elaboratore tenuto presso la SIAE non costituisce un’attestazione dell’originalità ed è facoltativa ai sensi della legge sul diritto d’autore.
Sul processo di Astrazione
Una prima limitazione dei confini da analizzare viene dalla necessità di differenziare l’idea dalla espressione altrimenti definibile come implementazione dell’idea.
Quindi il requisito funzionale associabile all’idea non può e non deve essere considerato come parte creativa del progetto mentre il codice programma rappresenta il vero oggetto da analizzare.
Sul Filtraggio
La correlazione tra i due insiemi di sorgenti può essere attribuita a diversi fattori. Di seguito una lista di possibili cause di correlazione non legate a contraffazione di software:
- Algoritmi Comuni:. Si fa riferminento ad un insieme di istruzioni utilizzati dalla maggior parte dei programmatori che implementano un certo algoritmo. Ad esempio il codice sorgente che effettua l’ordinamento alfabetico dei nomi. Tali algoritmi venono insegnati nella maggior parte delle aule universitarie e possono essere trovati nei più popolari testi di programmazione. Le linee di codice legati a questi algoritmi comuni potrebbero generare un alto grado di correlazione tra programmi pur essendo tali programmi sviluppati da programmatori diversi.
- Identitifativi Comuni delle variabili. Ci si riferisce ad alcune convenzioni utilizzate dai programmatori per attribuire dei nomi alle variabili. Ad esempio l’identificativo result attribuito al risultato oppure point attribuito ad un puntatore.
- Codice Sorgente di Terze parti: è una causa di correlazione molto frequente legata all’utilizzo di codice di terze parti utilizzato da entrambi i programmi.
- Codice Autogenerato: Ad esempio il codice presente nelle forms spesso è ricavato tramite wizard
- Autore Comune: Può succedere che lo stesso autore ha sviluppato due programmi con elementi creativi diversi a volte anche legati a funzionalità diverse mantenendo lo stesso stile di programmazione.
Sulla Comparazione
Più volte, nelle note di parte convenuta, sono stati citati i punteggi forniti dal prodotto CodeMatch (score) contestando l’introduzione da parte del CTU del grado di correlazione che apparentemente è in contraddizione con il suddetto score.
Già si è spiegato che il punteggio nei due casi è legato a due confronti diversi; lo score di codemtach confronta due file sorgenti mentre il grado di correlazione confronta due procedure. In generale l’obiettivo del presente paragrafo è illustrare come si arriva allo score di Codematch anche per capirne la valenza.
La trattazione completa circa il calcolo dello score richiederebbe molte pagine e sarebbe decisamente poco interessante, per cui ci si è concentrati sulla correlazione legata alle istruzioni.
Score di correlazione delle istruzioni
Indichiamo con F1 il file sorgente 1 originario e con F2 il File sorgente 2 che vogliamo confrontare con il file originario.
Lo score finale legato alla correlazione degli statement (istruzioni) è una funzione del numero delle linee di codice in comune tra i due listati ed è un valore normalizzato per cui è necessario attribuire un valore al file originario.
L’attribuzione del valore nel tool Codematch non è fatto semplicemente contando il numero d’istruzioni ma dando uno score ad ogni istruzione contanto i caratteri alfanumerici e non alfanumerici.
I caratteri alfanumerici hanno un peso maggiore (sono moltiplicati per 10) mentre i caratteri non alfanumerici (le parentesi, gli spazi etc etc) hanno un peso minore.
Quindi
L’istruzione
If Empty(cserx)
avendo 15 caratteri dei quali 3 non alfanumerici assume il valore 12*10+3= 123
Mentre l’istruzione
Scan For !ordint And !dispm And Empty(dcc) And !Empty(dcr) And dep.subdep
Avendo 73 caratteri totali 18 non alfanumerici quindi score = 550+18=568
Con le regole di cui sopra si arriva a dare un punteggio al file F1 che chiamiamo µs (F1) ed un punteggio alle istruzioni trovate in entrambi i listati che chiamiamo µs (F1,F2).
Lo score è ricavato dalla seguente equazione.
ρs (F1,F2)=(µs (F1,F2))/(µs (F1) )
Lo score per le variabili, le sequenze ed i commenti è ricavato con criteri simili.
Indicando con ρs (F1,F2) lo score legato al match delle istruzioni uguali,
con ρI (F1,F2)lo score legato al match delle variabili uguali
e con ρq (F1,F2) lo score legato al match delle sequenze uguali,
lo score globale è calcolato secondo la formula della seguente equazione:
![]()
dove non è stato incluso lo score dei commenti.
Quanto sopra rappresenta in estrema sintesi l’algoritmo utilizzato dal programma CodeMatch.
E’ un programma che fa bene il suo lavoro ma l’assunzione che una istruzione lunga pesi di più di una breve è valida nella maggior parte dei casi ma non quando si effettua una chiamata a procedura.
Una singola istruzione potrebbe essere più importante di una sequenza di dichiarazioni o di assegnazioni.
Per una trattazione più esauriente consiglio il libro di Bob Ziedman “The software IP Detective’s Handbook”
Sulla Valutazione
Per la valorizzazione consiglio di adottare un metodo basato sul conteggio delle linee di codice (a meno che non abbiate disponibili informazioni di dettaglio per consentire un calcolo mediante funcion point).
Un possibile metodo è il COCOMO II con “Development Model” Post Architecture.
Tale metodo fornisce risultati attendibili solo a valle di una definizione molto precisa del numero delle linee di codice e del costo persona su base mensile.
Secondo il modello COCOMO Il costo è stimato come una funzione matematica di attributi di prodotto, progetto e processo i cui valori sono determinati dai manager di progetto
L’attributo di prodotto usato più comunemente per la stima dei costi è la dimensione del codice
I moltiplicatori riflettono l’esperienza degli sviluppatori, i requisiti non funzionali, la familiarità con la piattaforma di sviluppo ecc.
- RCPX:complessità e affidabilità del prodotto
- RUSE: il riuso richiesto
- PDIF: difficoltà della piattaforma
- PREX: esperienza del personale
- PERS: capacità del personale
- SCED: programma di lavoro richiesto
- FCIL: funzionalità di supporto del team
Questi moltiplicatori incidono sul fattore correttivo.

Hello! This is my first visit to your blog! We are a group of volunteers and starting a new project in a community in the same niche.
Its such as you read my thoughts! You seem to grasp a lot approximately
this, such as you wrote the ebook in it or something.
I think that you can do with some % to force the message house a little bit, however other than that, this is excellent
blog. A great read. I’ll definitely be back.
Thank you for another informative website. Where else could I get that type of info written in such a perfect way? I have a project that I’m just now working on, and I’ve been on the look out for such information.