




Business Continuity per un sistema Complesso
Nelle riunioni il termine “business continuity” è sempre molto “cool” eleva i toni e fornisce a tutti la sensazione di fare qualcosa d’importante. Purtoppo qualcuno attribuisce al temine un significato sbagliato quindi vale la pena sffermarsi sulla definizione partendo da quello che dice wikipedia:
Per Business Continuity Management si intende un processo gestionale olistico che identifica potenziali minacce a un’organizzazione e gli impatti sulle attività che quelle minacce, se realizzate, potrebbero causare, e che fornisce un framework per costruire resilienza organizzativa con la capacità di un’efficace risposta a un evento critico che salvaguardi gli interessi degli stakeholder chiave, della reputazione, del brand e delle attività che creano valore.
Mi sembra un buon punto di partenza perché tira fuori il termine “olistico” di solito associato non ad un approccio scientifico analitico ma ad uno filosofico finalizzato allo studio dei sistemi complessi da intendersi non come semplice somma di componenti.
Il sistema complesso a cui facciamo riferimento è l’organizzazione che realizza un business secondo un proprio modello e che non deve essere vista come un insieme rigido di componenti come se fosse una macchina (come la vedeva Taylor) ma come un sistema adattabile, flessibile ed instabile.
Capite bene che con questi presupposti realizzare la business continuity è una grande sfida perché siamo soggetti all'”effetto farfalla” dove piccole perturbazioni determinano grandi variazioni sul sistema che dovrebbe reagire cambiando l’equilibrio e l’unica azione possibile è quella di basare la resilienza organizzativa sullo sviluppo delle competenze negli individui e nei team.
Stiamo andando ben oltre l’ambito esclusivamente informatico, includendo nel nostro perimetro l’intera organizzazione e la sua capacità di continuare a erogare prodotti o servizi a livelli predefiniti accettabili a seguito di un incidente.
Il primo obiettivo, prima ancora di studiarci lo standard ISO 22301 deve essere quello di ridurre il grado di complessità del sistema azienda a livelli accettabili per poter applicare il processo di BCM (Business Continuty Management). Come conseguenza si possono definire i seguenti postulati come condizione necessaria per l’adozione del BCM:
- Il Board e l’executive management deve essere ingaggiato e deve sostenere con forza l’adozione del processo BCM (postulato vero per tutti i processi di governance).
- Vanno defimiti in modo collegiale (e quindi con tutte le linee di business) i processi di business chiave per l’azienda (nel seguito Key Business Process o KBP).
- Ogni processo di business deve avere un owner (nel seguito Business Owner) nominato dal senior management (Accountable sul processo) e con un obiettivo chiaro e misurabile sul BCM
- I processi di business aziendali ed in particolare i KBP devono essere noti a tutti i dipendenti mediante un programma di awareness ed un KMS (Knowlwdge Management System).
Quanto sopra potrà sembrare banale ma non lo è. In particolare in un paese come il nostro dove il termine “Accountability” non ha nemmeno una traduzione italiana chiara. Essere accountable per un processo di business vuol dire assumere un ruolo molto importante non solo finalizzato a produrre fatturato ma anche a misurare il processo stesso, analizzare i rischi valutandone l’impatto e implementare contromisure finalizzate a gestire il rischio stesso.
Quando un processo è mutevole nel tempo e non è noto a priori quale potrebbe essere la sua evoluzione occorre implementare il processo ciclico (Plan-Do-Check-Act) anche detto ciclo di Deming.
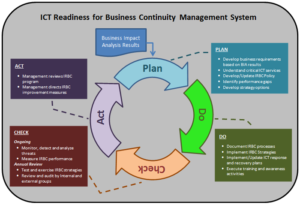
Il ciclo di Deming è come il prezzemolo lo trovate in quasi tutte le presentazioni agli eventi di Sicurezza Informatica (e non solo!) e la maggior parte delle persone pensa che sia una roba teorica, sia “fuffa”, un semplice diagramma finalizzato a rendere più elegante il proprio discorso. Nulla di più sbagliato perché va sempre contestualizzato per comprenderlo appieno.
Nel nostro caso la prima applicazione del ciclo di Deming avviene a livello di azienda ovvero di programma di business continuity dove il ciclo va applicato all’infrastruttura di gestione che va pianificata (PLAN), implementata e gestita (DO). monitorata e revisionata (CHECK) ed infine mantenuta e migliorata (ACT).
Questo vuol dire che l’infrastruttura di Gestione della Business Continuity si basa sul ciclo di continuo miglioramento Plan-Do-Check-Act applicato in modo continuativo su più livelli dell’organizzazione e sull’approccio sistemico allo scopo di identificare, capire e gestire i processi tra loro correlati contribuendo all’efficacia ed all’efficienza dell’organizzazione nel conseguire i propri obiettivi.
A questo punto vediamo in cosa consiste un’infrastruttura di gestione della business continuity magari con qualche semplificazione finalizzata ad una migliore comprensione del tema. Un possibile approccio (ma non è l’unico) è quello di identificare in azienda le entità da mettere sotto continuità operativa, ad esempio:
- Uffici più importanti
- Siti Tecnici (Datacenter, pop di rete o centri di supervisione e controllo)
- Processi di Business chiave
Il “collante” è rappresentato dal processo di security incident management dove viene dettagliata la procedura da seguire a fronte di un evento disastroso (trigger del processo).
quindi in questa prima fase (PLAN) del primo ciclo di Deming:
- Occore spendere del tempo per vedere come le varie entità sono collegate tra di loro verificando come i sistemi informatici (e quindi i siti tecnici) supportino i processi oppure che processi di business siano legati agli uffici.
- Occorre pianificare uno studio finalizzato a valutare la business impact anslysis per i processi chiave indentificati con l’obiettivo di verificare l’impatto finanziario del fermo dei vari processi al trascorrere dei giorni.
- Bisogna impostare una governance con un responsabile del programma (Business Continuity Leader) e dei reponsabili per ogni processo di business, ufficio o datacenter.
La BIA fatta prima di innescare il BCM è fondamentale e rappresenta, se commissionata a chi sa fare questo mestiere, la base su cui costruire il framework, fornendo uno quadro a 360° degli impatti.
Sulla base della mia esperienza un possibile approccio è quello di identificare, partendo dai dati dell’ultimo bilancio, a fronte di un blocco totale del processo di business:
- Costi giornalieri (Perdita fatturato non recuperabile, Interesti sul fatturato recuperabile, perdita produttività)
- Costi iniziali (Penali, Costi di ripristino Processo)
- Costi non quantificabili (danni d’immagine)
Il fatturato recuperabile è ad esempio quello derivante dai canoni di clienti già acquisiti mentre quello non recuperabile è quello relativo a nuovi clienti e quindi a nuovi ordini.
Quanto sopra è un’analisi da effettuare su ogni processo di business ed è uno dei passaggi fondamentali per individuare il tempo massimo sopportabile dal business di fermo del processo stesso (paramentro noto in letteratura come RTO ovvero Recevery Time Objective).
Inutile dire che quello che succede in pratica è che, in assenza della BIA a monte di tutto, il process owner interpellato se la cava chiedendo un RTO di poche ore a prescindere. In più di vent’anni di esperienza non ho mai visto un process owner dichiarare RTO di mesi perché molto spesso non hanno la visione d’insieme di tutti i processi di business aziendali ma solo di quello da loro gestito.
Fate anche voi una prova chiedendo al responsabile del delivery a quello dell’assurance ed al responsabile della fatturazione quale potrebbe essere il tempo consentito di blocco dei sistemi e/o del loro processo di business.
Nella fase implementativa (DO) si eseguono i passi precedentemente pianificati predisponendo la documentazione (BIA e Risk Assessment e Contingency plan o disaster recovery plan) ed eseguendo gli esercizi per testare i piani (CP o DRP).
Il Risk assessment è lo strumento chiave per capire come gestire i rischi sui vari processi di business e magari decidere di trasferire il rischio con una bella polizza oppure decidere di mitigare con un’infrastruttura di disaster recovery oppure decidere di non fare nulla perché la valorizzazione del rischio è molto bassa.
I piani di contingency dei processi, degli uffici o dei siti tecnici (chiamati usualamente disaster recovery plan) sono dei piani molto dettagliati contenenti tutti gli step da seguire in caso si verifichi un trigger (incendio di un building, allagamento, malattie epidemiche del personale etc etc). E’ fondamentale in questi piani riportare le già citate dipendenze uffici-processi e processi-sistemi che dovranno essere validati nella fase successiva di test.
Nella fase CHECK i piani vanno testati (di solito ogni sei mesi) ogni volta provando un trigger diverso e verificando con tutti gli attori la completezza del piano e raccogliendo i feedback. Questi test possono essere invasivi (cioé con impatto reale sui sistemi e processi) oppure tabletop (cioé simulati).
Questi esercizi dovrebbero essere la fase più importante che consentirebbe al board di apportare le opportune correzioni nella fase ACT invece vi assicuro che si traducono spesso in una squallida messinscena via call conference finalizzata a smarcare il task per potersi dedicare a cosè più importanti.
Quindi il disaster recovery plan è solo uno dei piani previsti all’interno del BCM ed il requisito di RTO per i diversi sistemi non è che una conseguenza della BIA e del valore di RTO dei processi di business collegati. Oltretutto non è detto che un processo di business non possa andare avanti anche senza sistemi quindi occorre valutare attentamente le dipendenze.
C’è un altro parametero che spesso compare nei requsiti del BCM ed è il valore di RPO (Recovery Point Objctive) cioé la frequenza di refresh dei dati sul sito di DR. Se faccio il DR con i tape con i backup fatti ogni settimana allora RPO sarà di 7 giorni altrimenti se allineo i due storage in termpo reale con connessione sincrona allora RPO sarà uguale a zero.
Se il vostro compito è gestire 700-800 server e replicare 30-40 TB in un sito di backup scordatevi di fare il DR con i tape perché è una strada impraticabile per tantissimi motivi tra i quali vi cito l’impossibilità di fare backup su tutti i sistemi allo stesso istante temporale o fare dei test del DR in tempi ragionevoli (ci vogliono settimane solo per i restore). Anche la replica remota della virtual library con sistemi di deduplica non mi convince perché riduce il rischio di tape non leggibili ma lascia inalterati i problemi di cui sopra.
In questo caso l’unica soluzione praticabile è quella di replicare gli storage in modalità sincrona o asincrona (a seconda della distanza) e acquistare delle macchine laddove dalla BIA escano dei valori di RTO dell’ordine delle ore o giorni.
Arriviamo in chiusura alle note dolenti legate all’applicazione del BCM nelle aziende. Il primo errore è quello di nominare un BCL (Business Continuity Leader) nelle strutture tecniche mentre invece la figura giusta è da ricercare nelle strutture di staff del board.
Questo errore (tutto del board e dell’executive management) è più generale ed è quello di non operare una netta distinzione tra i ruoli di governance e quelli di management forse perché molti non hanno chiare le differenze.
La governance nasce con l’obiettivo di indirizzare le linee strategiche dell’azienda mediante policy, audit e review e di fornire gli strumenti di controllo affinché questo avvenga.
La governance è responsabilità del board e dell’executive management non dei manager che invece si devono occupare di progettare delle procedure che implementino le policy.
Dare il ruolo di BCL (di fatto il programme manager del BCM) ad esempio ad un IT Operation manager è un errore che di fatto invalida l’intero programma o progetto.
